Do these questions sound familiar?
After a company merge and now searching one by one in separate systems?
Feeling lack of efficiency of your ERP system’s integrated search engine?
Is a negotiation about to start and you need the latest information within seconds?
Interested only in exact or relevant search results and therefore needing advanced filtering options?
Losing tremendous manhours searching for information instead of executing higher value-added tasks?
Worried about access rights settings to sensitive company data?
If you are familiar with these issues or you have faced another challenge in getting business insights, you definitely need an intelligent enterprise search engine!
Welcome to the world of
intelligent search
In close cooperation
A prerequisite for making an appropriate business decision is the searchability and instant accessibility of company data. This requires a search solution that meets the highest level of user needs. In addition to providing the essential search and filtering functions, TAS Enterprise Search also offers convenience features, therefore it is the most optimal tool for finding the values delivered by TAS Tagger.
Besides that both solutions are integrable independently to the enterprise IT environment of the customer, combining their capabilities gives you a true insight engine.
Basic information
TAS Enterprise Search developed by Precognox is a domain/subject independent intelligent search solution tool based on the world’s leading open source Elasticsearch platform as well as on a wide variety of linguistic tools.
The solution makes the various data sources searchable whether it can be found in databases, emails, HTML pages, in PDF, DOC or other document formats. Web based contents collected by TAS Data Collector can also serve as the basis of the search process. See the framed side note. As a further benefit, TAS Enterprise Search may be integrated to the existing systems within the company. Read more about at the Integration with other services section.
Features of TAS Enterprise Search
TAS Enterprise Search engine can be optimized for special searching needs in order to make the search experience as convenient and effective as possible. Besides all of the essential enterprise search functions TAS Enterprise Search also provides a lot of specialized features.
Features
- intuitive, widely customizable and user-friendly UI
- lightning-fast result display even in case of parallel activity of numerous users
- instant access to original content
- clear-cut and easily manageable core functions
- sorting based on the customer’s requirements
- specialized filtering options by the values extracted by TAS Tagger (keyphrases, entities, categories, topics, languages, emotions, sentiment).
- search term highlighting in the result previews
- relevancy scoring according to compiled query
- typo tolerance
- advanced search options, when multiple search parameters can be entered at once with specified relation between them
- additional module for mass queries by TAS Enterprise Bulk Search
- customizable specific synonym dictionary compiled in TAS Thesaurus Manager
- access rights management
- saveable query templates
- result exporting option for BI tools as Tableau, Rapid Miner, PowerBI, Google Data Studio, IBM SPSS in different standard formats (CSV, XML, JSON)
- industry leading solution for person identification (names with misspellings, aliases, nicknames, initials, names written in different languages)
- location and organization identification
- search terms and trends analysis by TAS Search Log Analyzer
- additional help and support
Getting answers worldwide
Ignoring data outside the company weakens the effectiveness of making the right business decision. Strengthen your available company data by the power of structured contents purposefully collected from the World Wide Web. TAS Data Collector turns external data into internal, thus expanding the range of searchable information available in TAS Enterprise Search.
By the combination of internal data and the contents collected daily from external source, you will always be up to date, and that means an enormous business advantage. In addition, it is worth mentioning that also the search process turns much more efficient and convenient.
Search operators
Extremely complex and sophisticated search queries can be compiled by the standard search operators. We provide a Help documentation with details and examples to understand how to use these operators.
Supported languages
- Boolean operators: for intersections, for unions and to exclude specific documents
- Grouping terms: to form sub-queries
- Wildcard searches: single or multiple character wildcard searches
- Fuzzy searches: fuzzy searches discover terms that are similar to a specified term without necessarily being an exact match
- Proximity searches: a proximity search looks for terms that are within a specific distance from one another.
- Range searches: ranges can be specified for date, numeric or string fields.
How does an enterprise search engine work in practice?
Our product video gives you an easy way to learn how TAS Enterprise Search works.
Demo UI
You can easily get acquainted with the functionality of the TAS Enterprise Search and its associated modules through our introductory video and DEMO interface. Watch our video, which provides an insight into the user interface of the search engine, its operation, and the unique filtering and sorting options available. Through the DEMO UI, you can initiate searches among the contents of articles published on Precognox’s Hungarian and English language blogs. Search expressions can be in Hungarian or English, with the default language determined by your browser’s language settings. Try the TAS Enterprise Search for yourself and discover how this tool can facilitate the quick finding of information!
TAS Enterprise Search GUI
The user can see all the available details of a search result. For example:
- title
- source of the result
- creation date
- modification date
- relevant parts of the document with the searched term highlighted
- more detailed preview of a document
- or any other details which are available in the searched documents
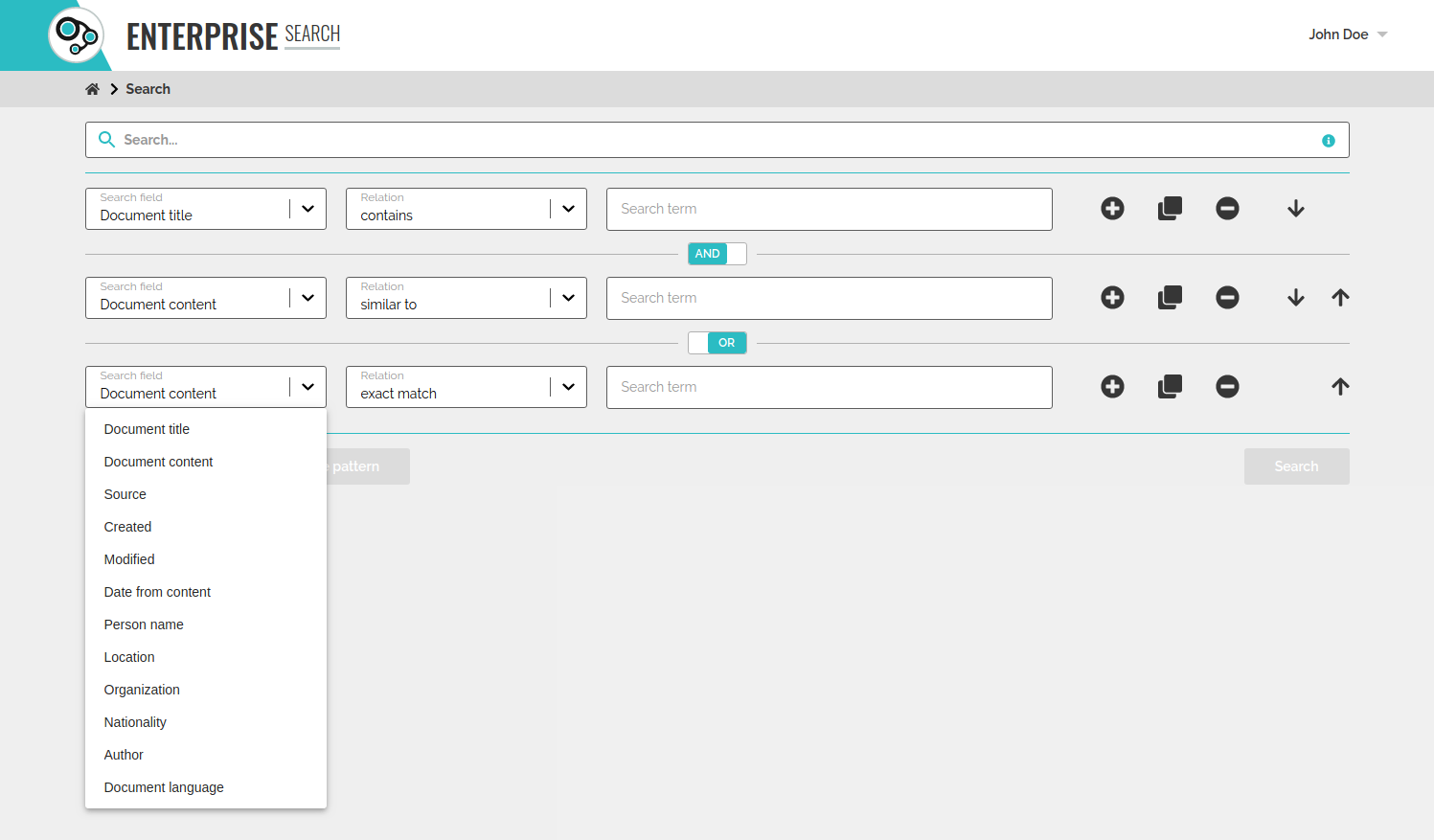
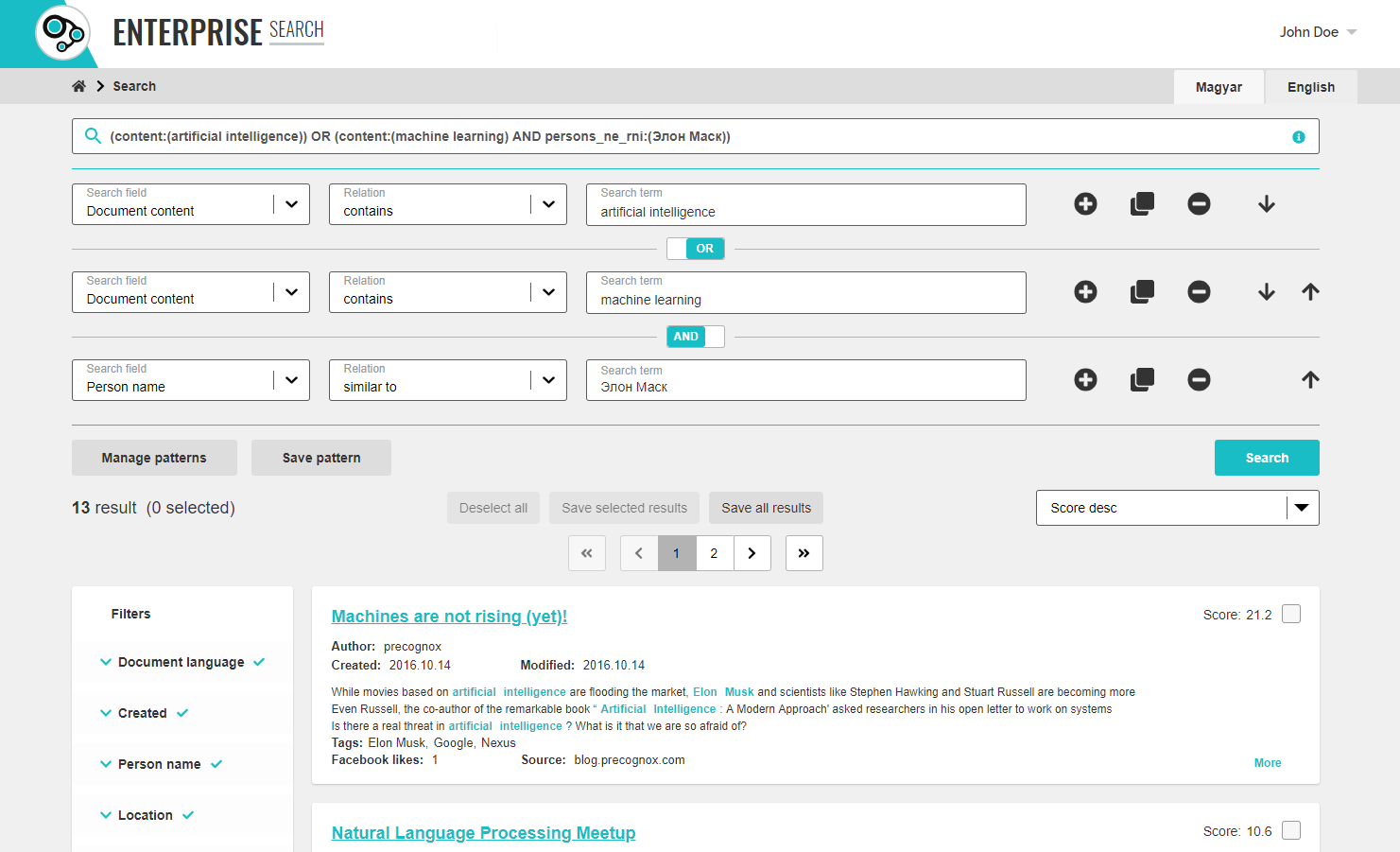
Enterprise Search Demo UI
We have also made a DEMO UI where you can get insight of how the search user interface looks like and how it works. The given example, “Blog Enterprise Search” is able to let you launch searches among the contents of articles published on our blog websites. The advanced search interface also provides the ability to filter and sort the results. The user interface and the search expressions may be English or Hungarian, the default language is defined by the language setting of your browser.
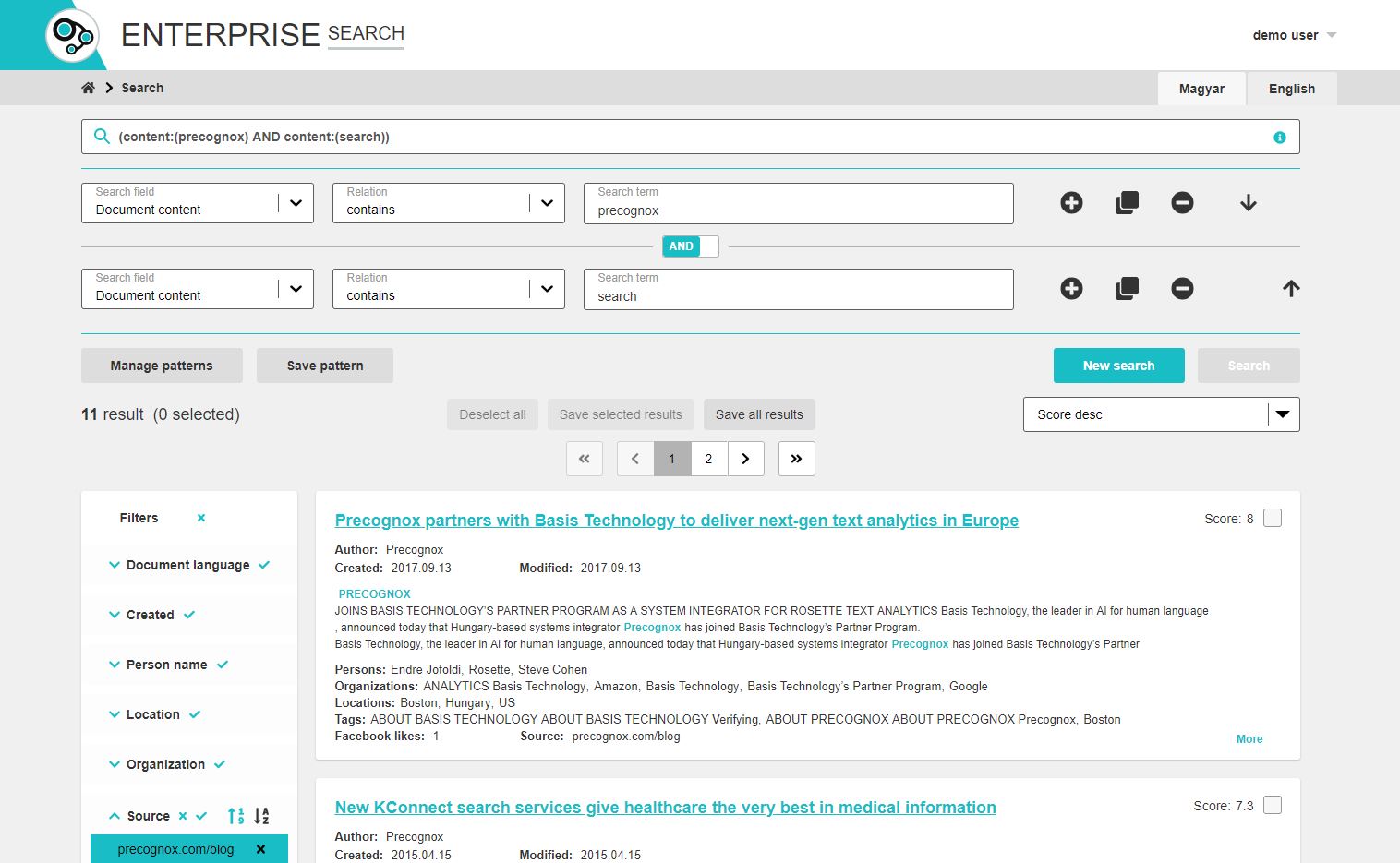
Technical features
TAS Enterprise Search solution is available within the confines of TAS Platform as Cloud service or On Premise.
The default look of the GUI is equivalent to TAS Platform but it can be re-designed to fit the corporate identity of the partner. The visualization of search results and other parts of the search user interface are also configurable. The particular solution depends on the customer’s needs.
Technical features
Lorem ipsum dolor ist amte, consectetuer adipiscing eilt. Aenean commodo ligula egget dolor. Aenean massa. Cum sociis natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus. Donec quak felis, ultricies nec, pellentesque eu, pretium quid, sem.
Other products of TAS Platform
We have also developed other software services in TAS Platform.
TAS Tagger is a tagging of your collected datasets automatically. Tagger helps you find the key expressions in the text. By the tags it is possible to find the connectivity points between different text bodies. One of the key application form is tagging articles in news websites or tagging a great amount of science contents or various business documents.
TAS Enterprise Bulk Search is a supplementary service for TAS Enterprise Search dedicated to simplify and shorten the complex and time-consuming search processes which previously could only be done one by one.
TAS Alarmlist is a text analytics solution for automatizing the time-consuming repetitive queries in the enterprise environment. The service sends notifications in several ways if it finds matches between company data assets and search terms contained in the compiled watchlist.
TAS Thesaurus Manager is a thesaurus-building module that facilitates the more optimal and sophisticated operation of the TAS Enterprise Search engine.
TAS Search Log Analyzer is a perfect solution if you have your structured database and it is searchable, you may be keen on getting information about the launched searches. TAS – Search Log Analyzer for example lets you know which keywords are used frequently or without any match. These and similar information can be used to continuously improve your search system.
TAS Data Collector is able to collect web-based data content in a structured format so as to make this content available for information systems or for further processing and analysis.
Technical description
Initial system requirements (On Premise)
Server with a Docker compatible Linux
16 GB RAM
x86_64 CPU at least 4 core
20 GB disk
Supported languages
All languages are available
Integration with other services
TAS Platform
Babel Street ROSETTE API
IBM Analyst’s Notebook
ABBYY FineReader Engine
Google Cloud Speech-to-Text
JIRA
Confluence
Onenote
Sharepoint
Alfresco
CMIS repositories
DropBox
Google Drive
HDFS
LiveLink (OpenText)
Documentum
Meridio
FileNet (IBM)
Email systems
Availability
- TAS Cloud (authentication / authorization)
- TAS On Premise (authentication / authorization)
- Standalone On Premise (without authentication)
Try and review
Try out the TAS Enterprise Search Demo and make a review on G2, Capterra or TrustRadius.
| TAS Enterprise Search Engine | Database search engine | |
|---|---|---|
| Ranking of the results | Sophisticated and complex | Poor |
| Speed | Rapid even for complex queries as it is optimized for text search | Unpredictable. (In case of common text search problems such as looking for prefixes or complex expressions, it is significantly slow) |
| Linguistic correctness | Handles various word forms (e.g. inflections) and relations between parts of an expression | Poor |
| Name indexing | Very advanced | Basic |
| Taxonomy (expert knowledge) | Available | None |
| Filtering results | Available for a wide variety of tasks | Needs custom solution |
| Combination of various data sources | Available for an arbitrary number of sources | Can only search in one database at a time |
| Handling PDF, DOC, XLS, HTML, XML and other document formats, OCR (Optical character recognition) | Available | None |
| Query interface/Presenting search results | Advanced and tailored according to needs | Needs custom solution |
| Modifying data | Scheduled according to needs | Immediate reindexing |
| Distributed, replicated data storage | Available | Available |
| LDAP / Active Directory support | Available | None |
Our company is a member of the Modern Enterprises Program – Venture Digitally! project, so we offer a 10% discount on our products to MVP Clients and Suppliers registered there! The product-related discount is a unique discount, which can only be validated by businesses registered as solution seekers on the www.vallalkozzdigitalisan.hu website. Register for the discount!